Python 爬虫的管理与定时任务
Scrapy 框架让我们很方便就能完成各种规模的爬虫项目,最简单的创建爬虫的方式:
- 创建一个项目
1 | scrapy startproject tutorial |
- 接着可以添加一个爬虫
1 | scrapy genspider -t crawl cambridge dictionary.cambridge.org/us/dictionary/english-chinese-simplified |
- 运行爬虫
1 | scrapy crawl cambridge |
我们可以按实际的业务需求重复第二步,创建大量不同目的的爬虫,但是如何管理这些爬虫呢?
Scrapy 官方文档推荐使用 Scrapyd 来管理,但实际操作起来稍显复杂,经过一番寻找和比较,发现了 Scrapy-do 这个项目,如果爬虫管理侧重定时任务方面,那 Scrapy-do 是一个更简单易上手的选择。
Scrapy-do 使用介绍
scrapy-do 是一个 scrapy schedule 项目,其特点在于提供了 web 管理页面,可以非常方便直观地管理爬虫任务。
安装
1
pip install scrapy-do
scrapy-do 实际上是一个 python server 项目,基于
twist框架,因此不论后续的什么操作,其实都是在和这个 server 通信。因此安装完成后,使用的第一步是启动 server:1
scrapy-do -n scrapy-do
这个 server 需要一直保持运行,建议使用后台任务
推送爬虫项目到 scrapy-do server
1
scrapy-do-cl push-project
注意,它不会直接访问你的项目,这一步其实是把爬虫项目工程放到它 server 的资源里,*因此,如果你的原爬虫项目有任何更改,务必再次执行此操作,保证它执行的是最新的项目代码
此时可以通过
scrapy-do-cl status查看当前的管理状态,或者直接访问它的 web 页面进行管理了(localhost:7654)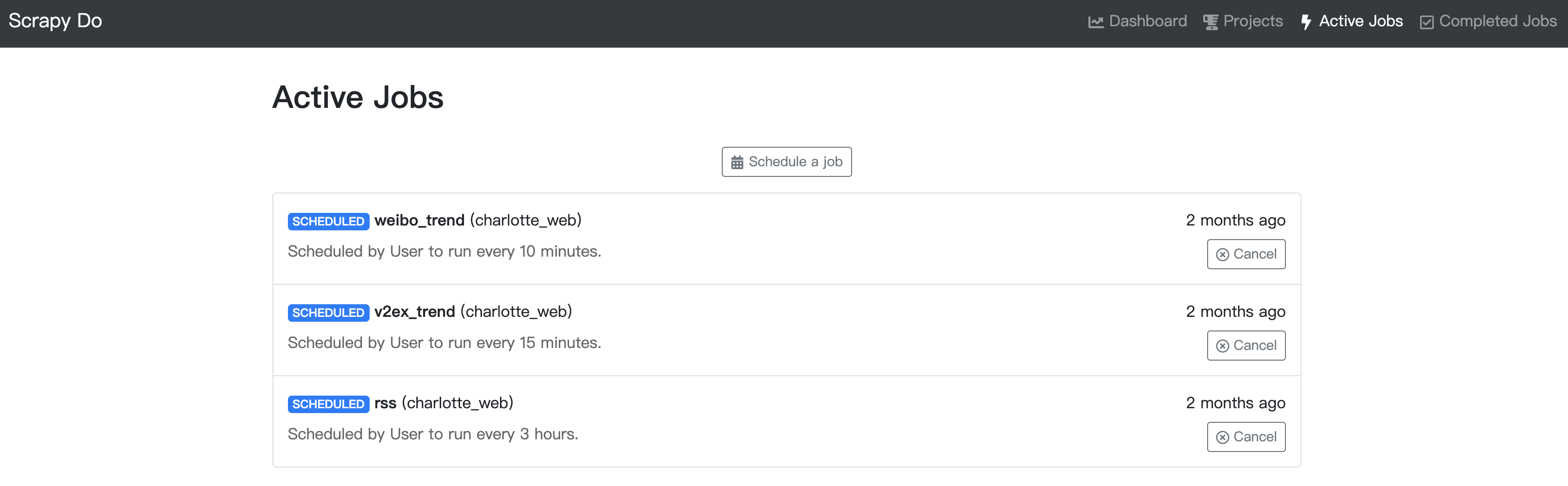
注意
默认只能本地机器打开 localhost:7654 才能访问,如果要自定义配置,需要创建一个配置文件,详情见文档,示例如下:
1
2[web]
interfaces = 192.168.31.22:7654 127.0.0.1:7654然后在启动服务的时候指定此配置文件即可:
1
scrapy-do -n scrapy-do --config sp-do.conf
爬虫项目通过 scrapy-do 执行的时候的网络环境和你的 shell 配置没有关系的,如果需要网络代理,需要直接在爬虫项目中进行设置